
在本章中,我们将探讨如何使用Python进行数据分析和可视化。数据分析是从数据中提取有用信息和洞察力的过程,而数据可视化则是将这些信息以图形的形式呈现出来,使得人们更容易理解和分析数据。Python在数据分析和可视化领域有着广泛的应用,其强大的库和工具使得处理大规模数据变得更加高效和简单。
8.1 数据处理与清洗
在进行数据分析之前,首先需要对数据进行处理和清洗。数据处理包括数据的加载、清洗、转换和整理,以便后续分析。在Python中,有许多库可以帮助我们进行数据处理,其中最常用的是pandas库。
8.1.1 数据加载与查看
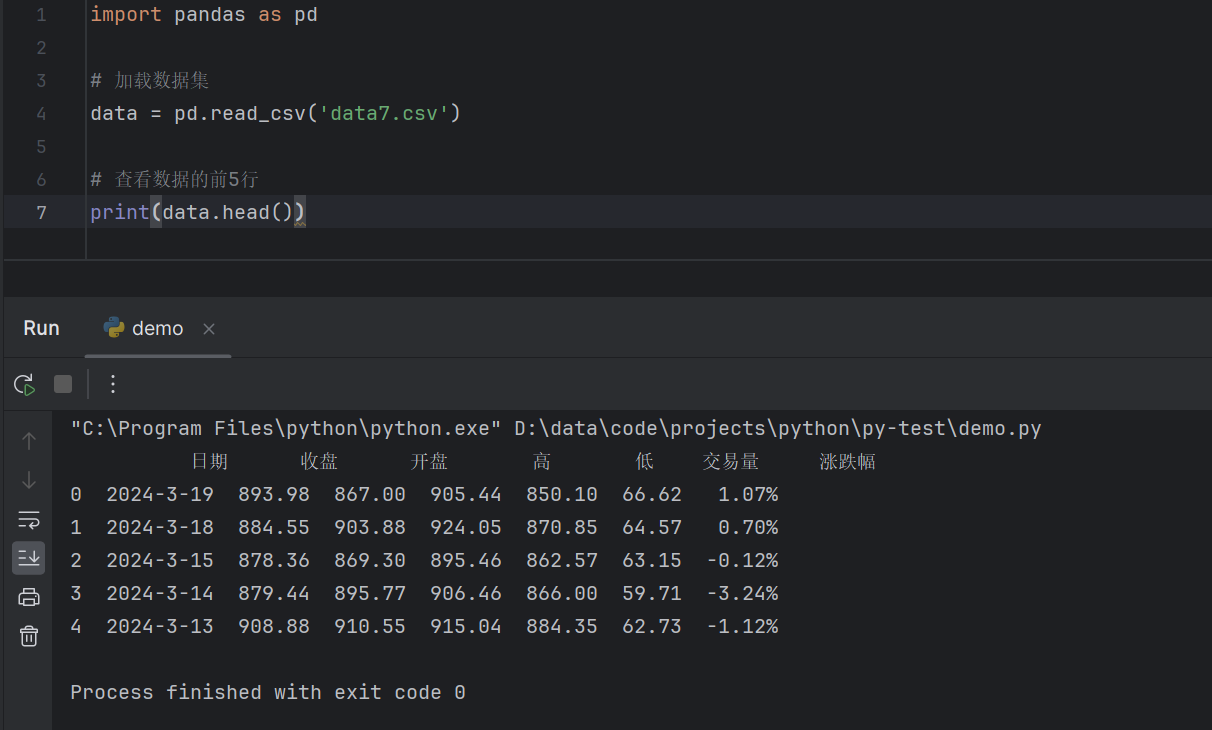
首先,我们需要加载数据集并查看数据的基本信息。pandas库提供了read_csv()函数用于加载CSV格式的数据文件,并且可以使用head()函数查看数据的前几行。
import pandas as pd
data = pd.read_csv('data7.csv')
print(data.head())
其中data7.csv文件内容如下:
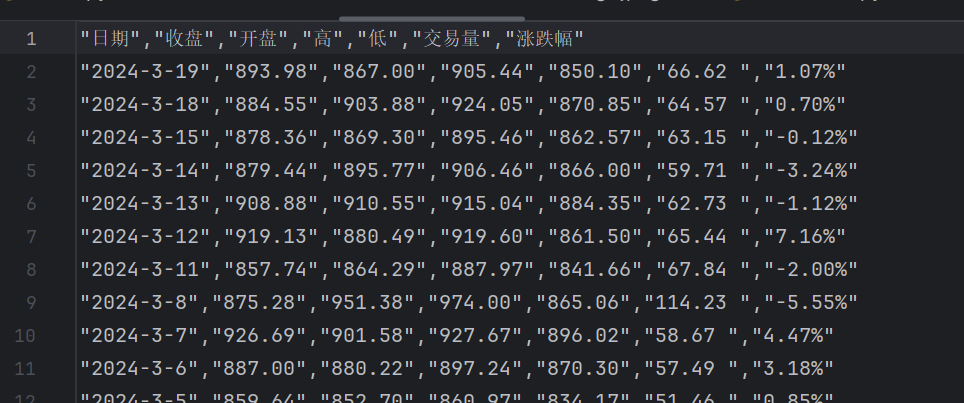
代码运行后效果如下:
8.1.2 数据清洗与处理
数据清洗是数据分析的重要步骤,它包括处理缺失值、异常值和重复值等。pandas库提供了一系列函数来帮助我们进行数据清洗,例如dropna()函数用于删除缺失值,fillna()函数用于填充缺失值,drop_duplicates()函数用于删除重复值等。
data.dropna(inplace=True)
data.drop_duplicates(inplace=True)
8.1.3 数据转换与整理
在数据分析过程中,有时需要对数据进行转换和整理,以便后续分析。pandas库提供了丰富的函数和方法来进行数据转换和整理,例如groupby()函数用于分组聚合,merge()函数用于合并数据集,pivot_table()函数用于数据透视等。
grouped_data = data.groupby('category').sum()
merged_data = pd.merge(data1, data2, on